After a little, er, let’s call it discussion I had with a certain supplier recently, I decided to write down a few words on server reliability and how to measure and understand it.
Like so many things that touch statistics it is very easy to take statements like “99.7% reliability” at face value without understanding its implications.
First a few words on measurements. It is customary to only count the nines in the number; i.e. “99.7% reliable” has two 9’s in it, so we talk about “2 nines” or short “2N” reliability.
A salesperson would argue that the “.7” is closer to another nine than to a zero and so we “almost” have a 3N reliability. Well, no, the 7 in the end shows that the supplier is making efforts to achieve a 3N reliability but isn’t quite there yet, so it’s still only 2N.
It is probably best to think of the term 3N describing all values between 99.900 and 99.989̅, which clearly doesn’t include 99.7 or even 99.8. No, not even 99.89̅.
In some circumstances we might even only accept odd N-numbers, as they show the relevant service levels for high reliability computing, i.e. 3N, 5N and (rarely and very expensively!) 7N. But that might be going a bit too far here.
In practical terms
But what do these reliability numbers mean in practical terms?
A good way of explaining this to your boss might be to show how much server downtime one can expect at each service level.
Now, here comes a bit of maths: there are 31536000 seconds in one year (365 ⨉ 24 ⨉ 60 ⨉ 60) and if your server is 99.9% reliable (3N) it means that it will be up at least 3150446400 of those.
Nice, but that implies it may be down for up to 31536 seconds (0.1%) or 8 hours, 45 minutes and 36 seconds. In other words: about one working day.
For an overview, it is good to know how each level translates into downtime per year:
| Reliability | Max. downtime/year | |
|---|---|---|
| 1N | 90% | 36 days, 12 hours |
| 2N | 99% | 3 days, 15 hours, 36 minutes |
| 3N | 99.9% | 8 hours, 45 minutes, 36 seconds |
| 4N | 99.99% | 52 minutes, 33 seconds |
| 5N | 99.999% | 5 minutes, 15 seconds |
| 6N | 99.9999% | 31 seconds |
| 7N | 99.99999% | 3 seconds |
Typically, this does includes both, planned maintenance (e.g. software updates, which can be scheduled outside peak hours) and unplanned events (e.g. power outages, etc. which can’t).
Also, they don’t typically come in one chunk (like, 3 days between Christmas and New Year) but in unexpected little off-times here and there; and typically just when they are most damaging to your reputation. So with this in mind, you definitely want to be in the 7N-tier for your web service.
But then you look at the price list for the higher reliability hosting solutions, and you’re suddenly not so sure any more. You will find that the higher reliability comes at an exponentially higher cost; this is for good reasons as you will understand if you look at it in more detail (as I would encourage you to do):
A server is not just a bit of hardware that stands in the middle of nowhere but rather it needs electricity, needs to be connected to the Internet and it must be kept dry and cool. Let’s not forget, it also needs to get its software updated, at least to fix any security flaws that were discovered over time…
All of these may contribute to downtimes: the power supply may break, the ISP can have downtimes, too and the hardware may quite simply break or overheat and shut down.
At least for the higher reliability tiers it is therefore usual to plan all of these redundantly: your data centre probably has more than one energy supplier (and a battery back-up, called a “UPS” or “uninterruptible power supply”). There’s probably two or more independent Internet connections to the building and the network is planned so that there are no “single points of failure”.
Still, shit happens, like both power supplies may go down at the same time (e.g. because of the excavations on the site next door where somebody cut both cables at once), so the next step is a redundant data-centre at a different location, or even better: three them on different continents…
There are no limits to this, but unfortunately each additional measure will only increase reliability by a tiny bit (but still cost you a fortune).
In the end, it’s all down to what kind of service you really need: for most blogs and general information web sites, something between 2N and 3N is probably quite sufficient. If you are launching the next Amazon or Google, by all means, go for 7N or even more…
Server maths
Let’s look at some simple redundancy setups:
Firstly, in any setup that is a bit more complex than this WordPress blog, you will probably have multiple servers running your different services. A minimal setup could be to have a front-end (web) server and a database backend on another.
There are many advantages from such a setup, not least that it increases your security if you don’t expose your database server directly to the Internet.
Unfortunately, it also brings a clear disadvantage with reliability: as the entire system is down if any of its components is down, the reliability of the entire setup is now significantly lower.
The other setup variant is redundancy: two servers that work in parallel and serve the same services. For example, two web servers. If one of them fails, the other one can at least still provide a rudimentary (possibly slower and/or otherwise reduced) service.
There are mathematical models to calculate the reliability, but as I will show you in a moment they are not very useful here.
Still, firstly, to calculate the reliability of two services in series, use the following formula:
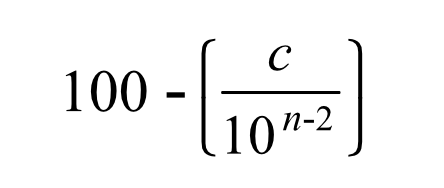
In this, c is the number of servers and n is our N-number as before. So for two servers (e.g. web and DB-server) at 3N this means: 100-(2/10) = 99.8.
While this is just a tiny decrease in reliability according to the numbers, it means that we have moved from 3N down to 2N – or in other words: the expected downtime for this service level doubles from 8 h 45 min to 17 h 31 min.
Except that it doesn’t. But more on that later.
Let’s also look at the other scenario: two servers in parallel.
The simple approach here is to add up the reliabilities, which can be expressed by the following formula:
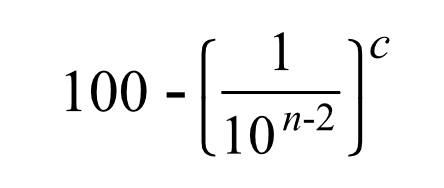
So again for 3N and two machines that would be: 100-(1/10)^2 = 99.99.
This time we moved from 3N to 4N which means we can expect 1/9 downtime. Great job!
Except it isn’t
Forget all the maths you’ve seen above. This is not how it works!
OK, don’t forget it completely. You can still use these formulae as some kind of “building blocks” for the actual calculations. It’s just that it isn’t as simple as this.
While the probability that one of the servers fails out of the blue is indeed better now that there are two of them, this only covers a very limited set of potential causes of failure. For other issues, there is either no change or things even got worse now.
- There are still potential points of failure that are outside of the server setup – power supplies, Internet connectivity, etc. – which will not be affected by this improvement.
- By adding a load balancer to switch between the two server, we have introduced a new “single point of failure” that wasn’t there before.
- If both servers use identical hard- and software, they may have identical flaws in them which may manifest at the same time.
The same also works in the other way, especially with the web server + DB server setup:
- If one server is taken offline for scheduled maintenance (e.g. software update), the other can be updated at the same time, i.e. without increasing the total downtime.
- Failure of a required (external) service (like power supply or Internet-connectivity) will typically affect both servers at the same time, not one after the other.
In short: if the downtime systematically affects all servers at the same time, it can only be counted once to the total downtime. Therefore it will not increase the total downtime of the system, no matter how many servers are affected.
To properly calculate the reliability of a server setup, all of this has to be taken into account. And in order to comprehend the calculation, a lot of information is required that the suppliers (probably for good reason, too) don’t want to give you.
But even if you can figure out all these parameters, it’s a rather complex calculation that has to take all the probabilities of all components and their probable “worst case” effects into account.
Conclusions
- If someone gives you an odd number of reliability (such as “99.7% reliable”) they are either clueless or intentionally trying to mislead you.
- Running a server with high reliability is expensive. Very high reliability is very expensive.
- Reliability doesn’t follow simple maths. It is complexity at its best (or worst).
- Always ask for details how the reliability has been calculated. You will need these details to calculate the reliability of upstream services (and to check if they did it right!)
In addition, you may want to:
- Check what happens if the supplier doesn’t fulfil his reliability promise; Will its CTO resign in disgrace or will they just send you a “we’re sorry” e-mail?
- Double-, no, tripple-check if the offer is really still so good once you know they have been cheating in the reliability numbers.
- Check other suppliers and then come back once you noticed they all cheat with these numbers and it’s really all the same.